
Executive Summary
The expansion of U.S. data-centre infrastructure is not governed purely by demand. While the AI economy continues to drive unprecedented appetite for computing capacity, the pace and geography of new development are increasingly dictated by physical infrastructure constraints. Geographically dependent constraints such as power availability, water access and zoning, act as binding limits that prevent capacity from scaling smoothly within traditional hubs.
The national data-centre footprint is changing. Texas is projected to overtake Virginia as the dominant centre of U.S. data-centre capacity by the end of 2026, driven by a substantial acceleration in large-scale campus development. At the same time, an increasing share of new capacity additions is occurring in states such as North Carolina, Georgia and Ohio, which are absorbing overflow capacity as the ability to expand in more saturated markets becomes increasingly constrained. Once initial infrastructure footholds are established, agglomeration effects can reinforce these positions, allowing emerging markets to develop into durable clusters rather than temporary spillover locations that merely absorb short-term capacity before growth recentres elsewhere.
However, this data-centre redistribution does not mean decentralisation. Instead, the industry is entering a phase where growth remains concentrated within geographic regions defined by infrastructure feasibility rather than potential demand concentration.
For operators, competitive advantage increasingly derives from securing long-term access to power. For investors, value will be distributed unevenly across regions, favouring areas with scalable infrastructure rather than simply strong demand fundamentals. For policymakers, power grid planning and permitting frameworks are becoming decisive factors in capturing future growth.
The long-term sustainability of emerging hubs depends not only on technical feasibility, but also on public acceptance. Concentrated data-centre development may place upward pressure on local utilities, introducing political risk that could shape future siting decisions. In this sense, the geography of AI infrastructure is not only a market outcome, as much as it is a policy outcome.
Introduction
In our previous article titled “Can Component Supply Keep Up with Data-centre Demand”,[1] we established that due to high demand for AI-driven applications and various supply-side constraints, that the scaling of data centres will not be as smooth as previously imagined. We determined that data-centre supply is primarily constrained by infrastructure components that cannot be easily scaled or substituted, thus leading to a redistribution of new capacity away from traditional hubs toward regions with scalable infrastructure capacity. This paper will explore what are the likely effects that these constraints will have in reshaping the geographic distribution of data centres across the United States.
Historically, data-centre development has clustered around a small number of established hubs such as Northern Virginia, Dallas-Fort Worth and Chicago, all benefiting from dense network connectivity, large enterprise customer bases, and economies of agglomeration. However, the supply-side issues identified in the previous article raise the question: will the next phase of data centre expansion follow similar geographic patterns, or will constraints force a more pronounced shift toward new areas?
Geographic distribution matters because it directly affects the cost, speed, and reliability with which computing capacity can be delivered. For hyperscalers and data-centre colocation operators, the ability to concentrate growth in a limited number of scalable regions can lower unit costs, simplify network architecture, and reduce time to market. Conversely, a more disjointed geographic footprint can increase complexity and reduce efficiency if done incorrectly.
As the transition to an AI-driven economy continues, understanding where capacity can realistically be built becomes as important as understanding how much capacity is demanded. This article therefore analyses the emerging regional winners and losers in U.S. data centre development, and the implications for those local economies.
Latency and Network Topology
Firstly, to identify where data centres would ideally be located, in a vacuum free from supply-side constraints, we must first identify the demand-side characteristics of an optimal location. In practice, the best location is determined by latency sensitivity and network topology[2].
At first glance, it may be natural to assume that population density determines where data centres should be built and historically, this has been the case. Placing computing capacity close to major population centres reduced latency and improved performance for internet-dependent consumer applications[3]. However, AI infrastructure operates differently. Once model response latency falls within an acceptable threshold, increased proximity to population provides no meaningful benefit. At that point, the decisive factor becomes whether a location can support scalable computing infrastructure rather than simply being closest to users[4].
This distinction is important because AI workloads increasingly prioritise concentrated computing capacity over population proximity. AI model training typically requires high internal coordination making intra-cluster performance the key focus. AI inferencing is more sensitive to latency. Delays between a user request and the model’s first response can affect the customer experience, although the degree of sensitivity varies depending on the application. Machine-driven applications are likely to be more sensitive to model response than human-driven interactions.
However, latency isn’t the only significant demand-side characteristic, network topology is also of great importance. A useful analogy is logistics infrastructure. A warehouse may be ideally geographically located, but if it is only connected by dirt roads, it cannot distribute goods efficiently. To operate at scale, it must be connected to highways and transport arteries that link it to the wider network. Data centres face a similar problem. Even a perfectly located facility cannot perform optimally in isolation; it must sit near high-capacity fibre routes. This dynamic helps explain how traditional hubs developed as central nodes within US internet architecture. Being situated near major fibre interconnection nodes was crucial to gain benefits from superior resilience and reliability. These interconnection points acted as attraction points for data centres, enabling operators to connect to a broad section of the Internet’s connectivity providers. As AI workloads become more compute-intensive and therefore economically costly, optimal placement needs to balance data-centre location with application latency boundaries, redefining what constitutes an optimal location.
Infrastructure Constraints and Location Feasibility
Unfortunately, the optimal location of a data centre is complicated by supply-side constraints. The previous article established that water, real estate and primarily power are the binding geographical constraints on data-centre expansion. These constraints do not simply slow growth; they determine where large-scale capacity can realistically be built. Therefore, a geographic redistribution reflects the movement of development toward locations that can sustain industrial computing power.
In practice, this balancing act favours locations that can deliver infrastructure certainty over those that are theoretically attractive from a demand-only perspective. The historical hubs now face increasing difficulty in securing additional power. Where expansion requires new generation or transmission upgrades, project schedules can stretch beyond the deployment window demanded by AI-driven workloads. In these cases, the constraint is not just cost, but the ability to deliver power at all within a useful timeframe. Locations that cannot meet those timelines are effectively removed from consideration.
As a result, operators redirect new capacity towards regions with surplus generation headroom or faster utility approval timelines, prioritising delivery certainty and scalability. In some cases, this includes securing long-term power purchase agreements to underwrite future supply. This shift should not be interpreted as a compromise against an ideal demand map. Instead, it reflects optimisation with supply-side feasibility. Growth concentrates around regions capable of supporting large compute campuses, where power infrastructure, contractor ecosystems and interconnection density reinforce each other.
This shift does not lead to even dispersal across the country. Instead, expansion clusters around a new set of corridors that mitigate multiple supply constraints simultaneously. Once a region can support large campuses, follow-on investment tends to accelerate because shared infrastructure lowers incremental risk and cost. The national footprint widens, but growth remains selective. The emerging data-centre map reflects not decentralisation, but re-clustering driven by production feasibility.
Using construction data from Baxtel, a specialist data-centre research and advisory firm, 4MC Partners conducted an analysis of current and planned total US data-centre capacity through to 2030, as shown in Figure 1.
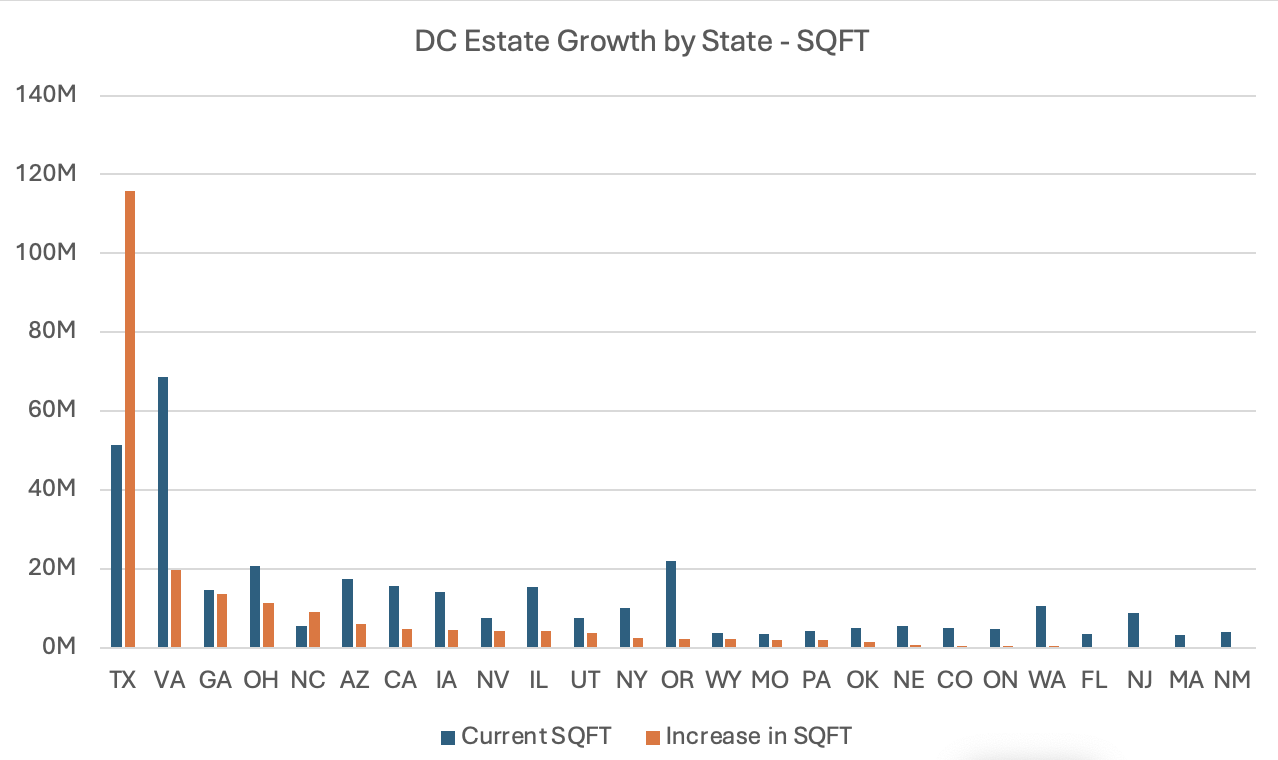 Figure 1- Data Centre Square Footage by State
Figure 1- Data Centre Square Footage by State
The most striking feature of the forecast is that Texas overtakes Virginia as the dominant centre of U.S. data-centre capacity, driven by an unprecedented increase of 116 million square feet, more than twice the state’s original footprint. In addition, several markets that were historically tertiary hubs are transitioning into credible secondary clusters. Because these projections reflect current visibility into the multi-year planning pipeline required to deliver new facilities, they provide a meaningful indication of where infrastructure momentum is already forming. Particularly notable are the outsized relative increases in states such as North Carolina, Georgia and Ohio.
Hyperscalers and data centre colocation providers remain the primary drivers of data-centre expansion, accounting for the majority of large-scale campus development. Focusing only on the split between these two groups (excluding other operator types), it is notable that a larger share of planned square footage through 2030 is flowing to colocation providers. Hyperscalers represent roughly 40% of the current footprint within this two-group comparison, but account for closer to 32% of the projected growth to 2030. The incremental build within this segment is therefore becoming increasingly colocation-led.
However, there is meaningful variation at the state level. In North Carolina, for example, approximately 68% of forecast growth within the hyperscaler-versus-colocation split is attributable to hyperscalers, indicating that development there is being shaped by a small number of large anchor deployments rather than broader multi-tenant expansion.
It is important to recognise that these increases do not necessarily represent entirely new geographic footprints. In many cases, they reflect capacity expansion within existing campuses rather than completely new developments. This distinction matters. Once a region establishes an initial infrastructure foothold, subsequent scaling becomes easier due to shared infrastructure and agglomeration benefits. Early-stage presence lowers incremental expansion costs and reduces execution risk, allowing secondary hubs to grow more rapidly than entirely new locations. As a result, regions that appear modest today may evolve into major strategic hubs as operational capacity comes online.
Economies of Agglomeration
Whilst supply constraints are widening the geographic footprint of data-centre development, they do not eliminate the economic forces that historically produced concentration. Data-centre markets exhibit strong economies of agglomeration[5], once infrastructure sufficiently exists in a region, the cost and risk of additional deployment fall as the required ecosystems are already in place. This dynamic is particularly evident among hyperscalers and established colocation providers, although some newer neocloud operators have shown greater willingness to locate in less traditional markets where power availability is the overriding constraint. Even when operators are forced to expand into new regions, they still prefer to build near an existing ecosystem rather than in an entirely undeveloped location[6]. The result is that expansion replicates clustering behaviour rather than dispersing across undeveloped regions.
This pattern is visible in the evolving geographic distribution of data centre locations.
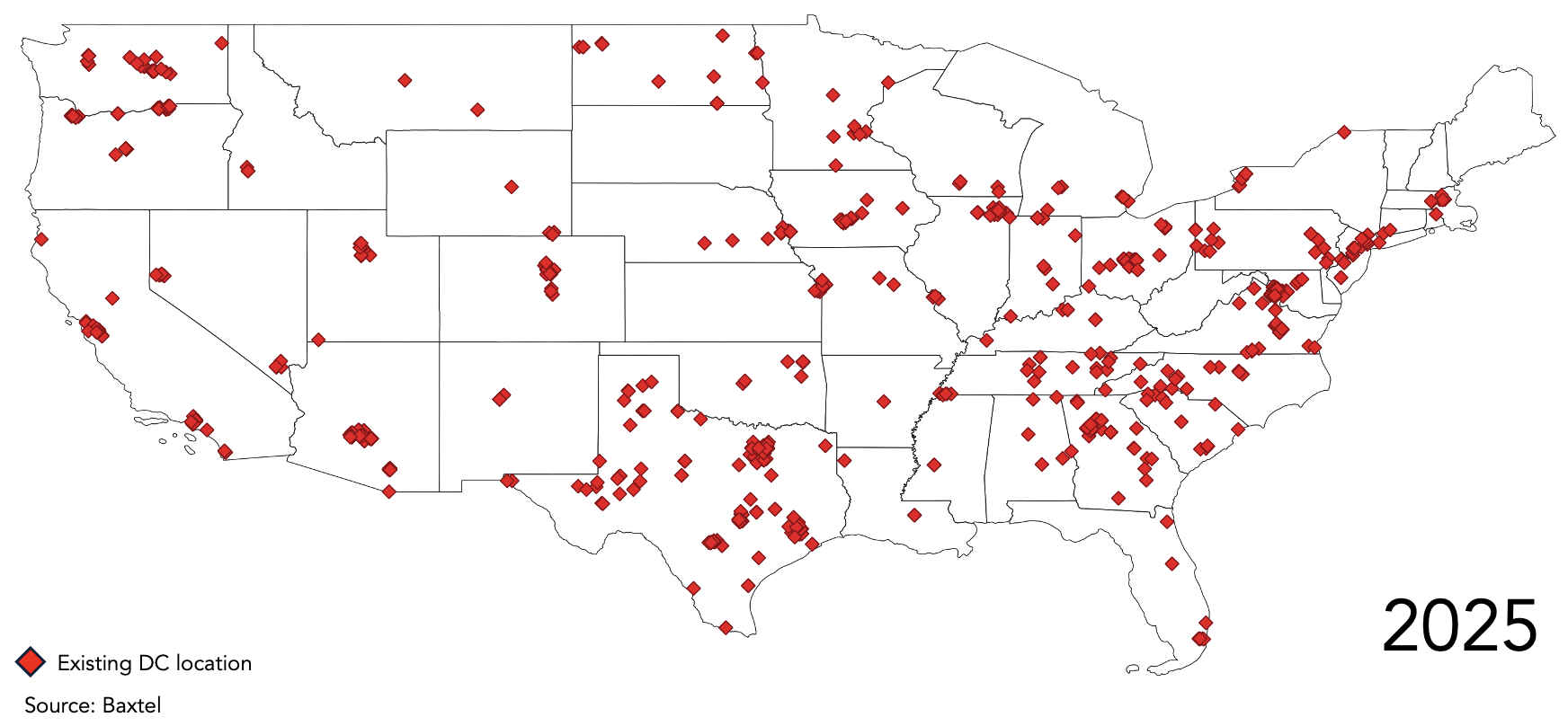
Figure 2 – Data Centre Locations in 2025
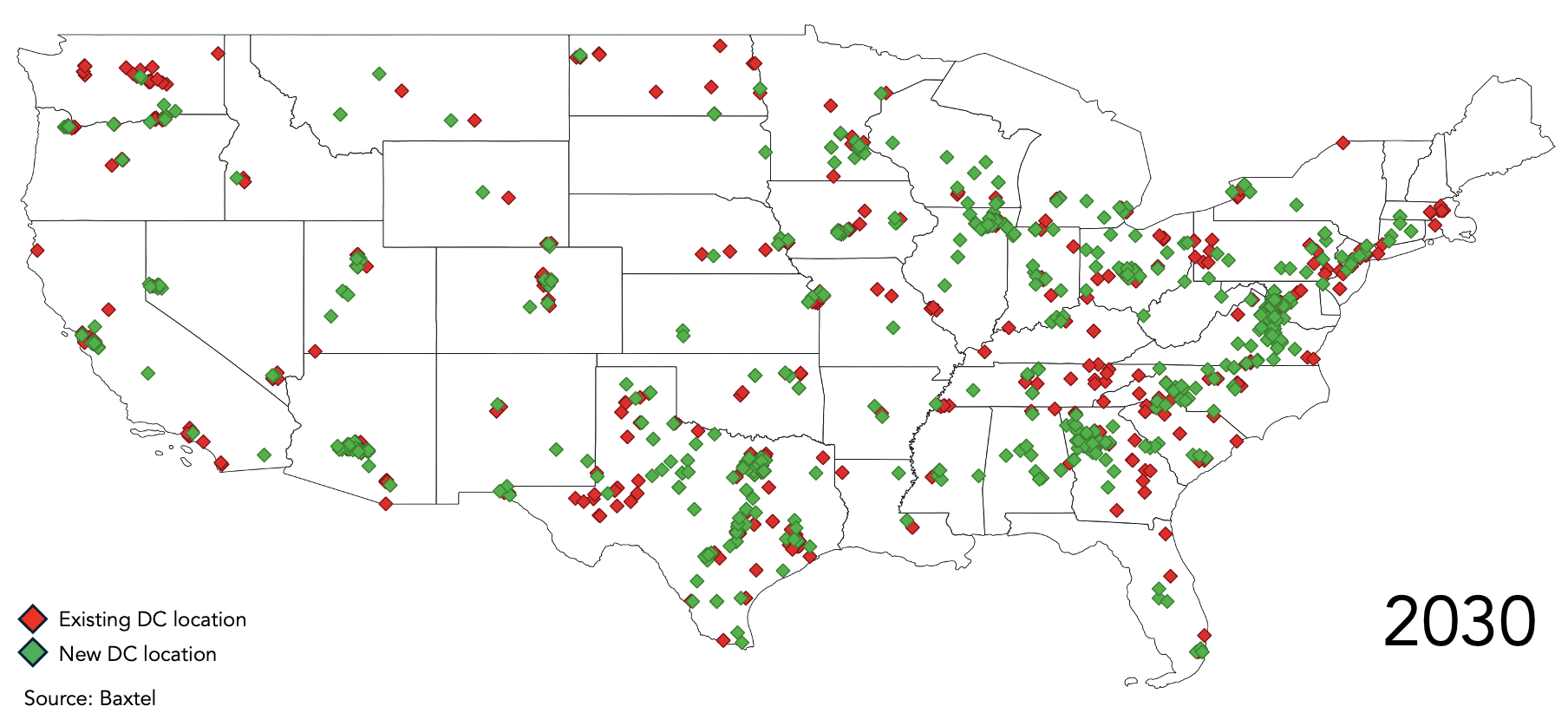 Figure 3 – Data Centre Locations in 2030
Figure 3 – Data Centre Locations in 2030
The projected distribution shows a broader footprint, but not uniform spread. Growth is still anchored in a number of identifiable hubs, even as new locations appear in power-advantaged areas. The pattern points to selective expansion rather than full decentralisation.
These agglomeration effects are accentuated by the network nature of digital infrastructure. Interconnection density increases the value of a location because each additional facility reinforces the performance and resilience of the wider network. Regions that reach a critical infrastructure threshold become self-reinforcing ecosystems, attracting data centre operators and enterprise customers alike. This feedback loop explains why secondary markets that successfully absorb early overflow capacity often transition rapidly into new strategic hubs rather than remaining peripheral outposts[7].
Therefore, the redistribution described in the constrained optimisation section should not be mistaken for a flattening of the national data-centre landscape. What we are seeing instead is constrained re-agglomeration. New clusters emerge where geography and regulation allow them to scale, but once established they behave much like legacy hubs: growth compounds locally rather than spreading evenly. This dynamic matters for long-term planning, because it implies the future map will be shaped by a small number of dominant corridors rather than a uniform national footprint.
Implications
The redistribution and re-clustering of data-centre capacity reshapes the strategic landscape for every participant in the infrastructure ecosystem. For operators, choosing data centre locations becomes less about demand density proximity and more about securing long-term access to constrained inputs, especially power. Competitive advantage increasingly comes from utility relationships, permitting capability, and the ability to identify regions with infrastructure headroom before they saturate. In this environment, site selection the core strategic decision.
For infrastructure investors, the shift implies that value will accumulate unevenly across regions. Markets that absorb early overflow capacity are likely to increasingly attract capital and rising asset values as clustering effects compound. Regions constrained by grid saturation may underperform despite strong theoretical demand. The decisive variable is whether the underlying infrastructure can scale. Therefore, investment theses built purely on demand projections risk overlooking the geographic bottlenecks that ultimately govern supply.
Policymakers and utilities face a similar challenge. A region’s ability to attract data-centre investment increasingly depends on grid capacity, interconnection timelines, and regulatory coordination. In some markets, data centre operators may turn to behind-the-meter or self-powered generation to reduce reliance on constrained grids, but these approaches do not remove the need for permitting certainty and fuel or transmission infrastructure. Regions that treat computing infrastructure as a form of industrial capacity, and plan energy systems accordingly, are more likely to capture sustained growth. Where infrastructure timelines lag industrial demand, investment will simply move elsewhere. The emerging geography of data centres is therefore shaped as much by policy decisions as by market forces.
In addition to reshaping infrastructure geography, large-scale data-centre investment can generate significant economic benefits for host regions. Construction phases typically involve substantial capital investment and support a broad base of contractors and specialist trades. Over the longer term, operational campuses create high-skilled roles across technical and facilities functions. Beyond direct employment, data centres contribute to local tax bases and generate additional activity across related service and supply chains. For regions seeking to attract industrial-scale investment, computing infrastructure can function as a long-term economic anchor.
However, there are political concerns. Data centres are extremely power intensive, and electricity is not a discretionary good; it is a foundational input into everyday living with no substitutes. Large-scale concentration of computing infrastructure therefore risks placing upward pressure on local energy prices. Whilst higher electricity costs can be absorbed to some extent by AI and infrastructure firms as a cost of doing business, the burden on households is more sensitive. If utility prices rise faster than local incomes, the result may be a reduction in living standards, particularly in regions with rapid data-centre expansion. Over time, this creates political and social friction, as communities begin to question whether the economic benefits of hosting data-centre infrastructure are being shared in an equitable fashion. In response, local communities may lobby for restrictions on further development, introducing increasing regulatory risk that can slow or redirect future capacity[8]. With this in mind, the long-term sustainability of emerging hubs depends not only on technical feasibility, but also on maintaining public acceptance.
Notes and Sources
[1]Can Component Supply Keep Up with Data-Centre Demand? https://4mc.partners/supply_and_data_center_demand/
[2] How Important Is Location When Choosing a Data Center?
https://www.datacenterknowledge.com/data-center-site-selection/how-important-is-location-when-choosing-a-data-center-
[3] Data Centre Location Strategy in the Age of AI, Data Centre Solutions.
https://datacentre.solutions/blog/58479/data-centre-location-strategy-in-the-age-of-ai
[4] Building Hyperscale AI Data Centers in Rural America with Wes Cummins, Baxtel Podcast Interview, 2026.
https://baxtel.com/podcasts/e9-building-hyperscale-ai-data-centers-in-rural-america-with-wes-cummins
[5] Top 10 U.S. Data Center Markets — and Why They Are Hot.
https://www.coresite.com/blog/top-10-u-s-data-center-markets-and-why-they-are-hot
[6] Global Data Center Trends 2025.
https://www.cbre.com/insights/reports/global-data-center-trends-2025
[7] Columbus emerges as major data center hub as Northern Virginia capacity tightens.
https://www.datacenterknowledge.com/data-center-markets/columbus-emerges-major-data-center-hub documents how power and land constraints in Northern Virginia pushed hyperscale expansion toward Columbus, which absorbed spillover demand and rapidly evolved from a secondary market into a major U.S. data-centre hub.
[8] QTS abandoned plans for a new data-centre near Madison, Wisconsin, after opposition from local officials, underscoring the growing political and community pushback against large computing facilities.https://www.datacenterdynamics.com/en/news/qts-drops-plan-for-data-center-near-madison-wisconsin-amid-opposition-from-local-officials/?mkt_tok=NjY1LUtYWS02OTcAAAGfru5Ty-XZy_WAFdJt4vgRoePj9NpnTfCQ2sTrTNGzpq-jzBHUT0Vu6AdHMyCi-Sc1IZ54qoB_zwpqlgjlie_rYDxt4tKQv41CxPALi2uPmKT9sTc5Gw